WIP 2026/06/23
UTF-8000
Unlimited UTF-8!
ASCII ⊆ UTF-8 ⊆ UTF-8000
No special cases introduced.
All properties preserved.
TLDR / Examples
| ASCII | |||||||||||
| 1 |
0xxxxxxx
|
||||||||||
| UTF-8 | |||||||||||
| 2 |
110xxxxx
|
10xxxxxx
|
|||||||||
| 3 |
1110xxxx
|
10xxxxxx
|
10xxxxxx
|
||||||||
| 4 |
11110xxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
|||||||
| UTF-8000 | |||||||||||
| 5 |
111110xx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
||||||
| 6 |
1111110x
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
|||||
| 7 |
11111110
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
||||
| 8 |
11111111
|
100xxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
|||
| 9 |
11111111
|
1010xxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
||
| 10 |
11111111
|
10110xxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
|
| ... | |||||||||||
| 22 |
11111111
|
10111111
|
10111111
|
10110xxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
| ... |
There is nothing special-case-y about the example 22-byte code unit here. It is just a good prototypical example, demonstrating the power of UTF-8000 with multiple start bytes.
There are only two special cases, both of which are inherited from UTF-8: ASCII as is, and 2-byte UTF-8 having 4 mandatory content bits to check against overlong encoding as opposed to 5 for all longer length code units.
Anatomy
Here is anatomical diagram of the example 22-byte code unit from the tldr.
See the glossary for more information on the definitions of the terms.
Byte number four is exciting! It is a continuation byte, a start byte, the final start byte, has content bits, and has only some of the mandatory content bits, which are straddled across the final start byte and first non-start byte.

The main contribution of UTF-8000's specification is clarity on splitting the highest bits of the first byte of UTF-8 code units into self-synchronization bits and start bits, and then making it clear how to stripe the start bits across the continuation bytes if needed, to achieve arbitrarily large code units.
Glossary
These terms are ordered somewhat by chronology of first requirement, rather than alphabetically, for convenience.
Terms used within definitions are underlined.
| Term | Definition |
|---|---|
Codepoint |
A non-negative integer, aka an unsigned integer. |
Code Unit |
A sequence of UTF-8000 bytes that encode a single codepoint. |
First Byte |
The first, one and only, byte that begins a UTF-8000 code unit.
The self-synchronization prefix of a first byte is either
This term is not synonymous with start byte. A first byte is necessarily a start byte, but not the other way around. It is for this reason that first byte is sometimes also known as first start byte.
Fun observation: because of the self-synchronization prefix
This term is mutually exclusive with continuation byte due to self-synchronization. |
Continuation Byte |
A byte beyond the first byte of a multi-byte UTF-8000 code unit.
The self-synchronization prefix of a continuation byte is
Fun observation: because of the self-synchronization prefix
This term is mutually exclusive with first byte due to self-synchronization. |
|
Self-Synchronization Prefix |
The highest bits of every UTF-8000 byte that indicate whether it is a first byte or a continuation byte. The possible self-synchronization prefixes form a prefix-free tree: This piece of the clever architecture of UTF-8, which UTF-8000 inherits, provides the property of self-synchronization at a byte level: we can instantaneously tell what kind of byte we are looking at, and where it should belong in a code unit, just by looking at these highest bits.
This is most useful when decoding part of a file encoded in UTF-8000. If we randomly seek through the file to an arbitrary byte, we can unambiguously tell whether we are at a first byte whence we can begin decoding a new code unit immediately, or that we are at a continuation byte whence we need to seek a little further on in order to find the next first byte in order to begin decoding. Nor do we have to process any bytes prior to our seek position in order to discover some global state or the context of the byte we have seek-ed to; a first byte is always unambiguously a first byte wherever it appears, which we can deduce by its self synchronization prefix being either This is useful not only for random access, but also for error recovery. Suppose that we are decoding an error-prone stream of UTF-8000 bytes and that whenever when we encounter an error (e.g. a rogue 0xC0 byte) we wish to See the Wikipedia article for self-synchronizing code for more general info. These bits are highlighted in bright cyan. |
Start Byte |
A byte containing one or more start bits. The start bytes exist contiguously at the beginning of a UTF-8000 code unit. The power of UTF-8000 is that we can have multiple start bytes, to achieve arbitrary code unit lengths, to encode arbitrarily large codepoints. Sometimes it is sensible to colloquially also include ASCII as a start byte when we are talking about the bytes towards the start of a code unit, even though ASCII bytes have no start bits. Every non-ASCII code unit has at least one start byte. The first start byte is the first byte, and it is followed by zero or more continuation bytes that are also start bytes. Therefore because a UTF-8000 code unit can have multiple start bytes, this term is not synonymous with first byte. In restricting to only UTF-8 without UTF-8000, this term is synonymous with first byte. This is because UTF-8-length code units only require one start byte, whether using up to 4 bytes in the current UTF-8 standard (RFC 3629 (2003)), or using up to 6 bytes in former standards (RFC 2044 (1996) and RFC 2279 (1998)). |
Start Bits |
The unary-code sequence of bits contained in the start bytes of a multi-byte UTF-8000 code unit that tells us the length of the code unit in bytes.
For a code unit made of The possible start bits sequences form a prefix-free tree: For an
This is another piece of the clever architecture of UTF-8, which UTF-8000 inherits, that provides the property of self-punctuation also known as a This avoids a problem of dumber variable-length encodings whose code units do not intrinsically indicate their length: one has to read beyond the last byte of a code unit, that is one reads the first byte of the next code unit, in order to know that the current code unit has finished. For very dumb encodings which have neither self-synchronization nor self-punctuation, to make random access possible one would have to put dedicated auxiliary bytes, See the Wikipedia articles for prefix code and unary coding for more general info. This term is mutually exclusive with content bits. These bits are highlighted in bright magenta. |
Content Byte |
A byte containing one or more content bits.
A byte being a content byte does not imply that it is a continuation byte. For example a 3-byte code unit begins with
A byte being a continuation byte does not imply that it is a content byte. For example a 22-byte code unit contains
|
Content Bits |
The sequence of bits in a code unit beyond the start bits and to the end of the code unit, in which the codepoint's binary bits are stored. For example a 3-byte code unit, which has the form
For ASCII there are 7 content bits. These seven bits Otherwise for an This term is mutually exclusive with start bits. These bits are highlighted in lime. |
Mandatory Content Byte |
A byte containing one or more mandatory content bits. These are the bytes we check for overlong encoding when decoding a code unit. |
Mandatory Content Bits |
The first 0, 4, or 5 content bits of a code unit in which there must be at least one For ASCII there are 0 mandatory content bits, and thus no anti-overlong checking is required. This is because ASCII is the smallest possible code unit. For 2-byte UTF-8000 there are 4 mandatory content bits. This is because in the jump from 1-byte ASCII to 2-byte UTF-8 we jump from 7 content bits to 11 content bits. Thus the number of content bits we gain is 11 minus 7 which is 4. Otherwise for Read about overlong encoding for why mandatory content bits are of interest. These bits are highlighted in bright lime. |
Overlong Encoding |
Forbidden
For example one could incorrectly try to encode the codepoint 0x41, 65, ASCII capital A, using 2-byte UTF-8 as
Security is one main reason why we forbid overlong encoding. For example we ensure that
Uniqueness of encoding is another reason why we forbid overlong encoding. Every codepoint has one unique valid representation as a UTF-8000 code unit, which is easy to encode and decode using bitshifting.
Fun observation: because all 4 of 2-byte UTF-8's mandatory content bits lie in the first-and-final start byte, we can explicitly rule out
|
Properties
Many of these properties of UTF-8000 are explained in detail in an appropriate section of the glossary and hyperlinks to the glossary are provided.
Bit Counts
The number of content bits and mandatory content bits are very predictable as a function of n, the length of a code unit.
| code unit length | number of content bits | number of mandatory content bits |
|---|---|---|
n = 1 |
7 |
0 |
n = 2 |
5n+1 ( = 11) |
4 |
n > 2 |
5n+1 |
5 |
Why the Special Cases?
As stated in the tldr, there are only two special cases, both of which are inherited from UTF-8:
1-byte UTF-8 (ASCII) which has two points of interest:
- It has 7 content bits which does not fit the pattern of
5n+1. See the glossary section for content bits for an explanation, and see the rejected alternative ASCVI code for a version of UTF-8 if ASCII were 6 bit instead of 7 bit which eliminates this special case. - ASCII has 0 mandatory content bits because it cannot possibly be overlong since it is the smallest possible code unit. This is fine.
2-byte UTF-8 which has one point of interest:
- It has 4 mandatory content bits, as opposed to 5 for all longer code units. See the glossary section for mandatory content bits for an explanation.
The remarkable fact that UTF-8000 does not introduce any new special cases in extending UTF-8 is confirmation to me that this is the canonical, correct way to extend UTF-8. In other words UTF-8 in its current restricted 4 byte form is UTF-8000, but only a small part of it.
The fact that we are even able to extend in the first place is also testament to the clever planning and care that Ken Thompson and Rob Pike put into the architecture of UTF-8, which we ensure to maintain as we extend to UTF-8000. Unary code codewords for the start bits sequences, which form a self-similar tree, were a great choice being simple and extensible. This is why I think of UTF-8 as the capstone of the Unix Philosophy.
Information Rate
What proportion of a code unit is content bits?
For ASCII this is 7/8 = 87.5%.
Otherwise for an n byte code unit this is (5n+1) / 8n, that is 5n+1 content bits out of a total of 8n bits from n bytes. We can rewrite this as (5/8) + 1/(8n) which moderately quickly approaches 5/8 = 62.5%. It is nice that this limit is nonzero and does not depend on n.
Self-Synchronization
Inherited from UTF-8 and maintained in UTF-8000.
See the glossary section for self synchronization prefix for an explanation of self-synchronization.
Self-Punctuation
Inherited from UTF-8 and maintained in UTF-8000.
See the glossary section for start bits for an explanation of self-punctuation.
Byte Map
Extended from UTF-8, making use of the higher value bytes. Based off Wikipedia's UTF-8 Byte Map.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ␀ | ␁ | ␂ | ␃ | ␄ | ␅ | ␆ | ␇ | ␈ | ␉ | ␊ | ␋ | ␌ | ␍ | ␎ | ␏ |
| 1 | ␐ | ␑ | ␒ | ␓ | ␔ | ␕ | ␖ | ␗ | ␘ | ␙ | ␚ | ␛ | ␜ | ␝ | ␞ | ␟ |
| 2 | ␠ | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | ␡ |
| 8 | ||||||||||||||||
| 9 | ||||||||||||||||
| A | ||||||||||||||||
| B | ||||||||||||||||
| C | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | ||
| D | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| E | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| F | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 5 | 5 | 5 | 5 | 6 | 6 | 7 | 8+ |
All bytes except 0xC0 and 0xC1 can appear in a valid UTF-8000 stream. See the glossary section for overlong encoding for an explanation of why those two bytes never appear.
strcmp(3) Ordering
Inherited from UTF-8 and maintained in UTF-8000.
The self-synchronization prefixes of first bytes are monotonically-increasing-ly ordered with respect to code unit length. In other words ASCII is of length 1 and multi-byte is of length greater than 1, and 0 < 11 occupying the highest bits of UTF-8000 bytes.
The start bit sequences are also monotonically-increasing-ly ordered with respect to code unit length. In other words if n < m then 111...[n]...10 < 111...[m]...10 as an integer value, occupying the heads of the code unit bytes beyond the self-synchronization prefixes. This would not have been the case had UTF-8 been designed to use the alternative form of unary codewords given by 000...01.
The content bits of code units are also monotonically-increasing-ly ordered with respect to codepoint value.
Combining these three things together means that strcmp(3), the C stdlib string comparing function, works the same way on UTF-8000 bytes as it does on UTF-8, as it does on ASCII, effectively comparing the encoded codepoint values against each other without having to actually decode the code units. Nice!
No Endianness
The quantum
of ASCII, UTF-8, and UTF-8000 is a single byte. This makes life a breeze! There is no need for a concept of endianness for UTF-8000.
UTF-16 however has a quantum of two bytes, 16-bit units. When writing the codewords in bytes, 8-bit units, should the byte containing the most significant digits or least significant digits be written first? Big-endian, or little-endian? This choice gives UTF-16 two variants, UTF-16-BE and UTF-16-LE. If one cannot predetermine the endianness of a stream, one may wish to use a BOM which is discussed below.
BOM Support
A Byte Order Mark (BOM) is used at the start of an encoded text stream to indicate what encoding is used. I have never actively used BOMs myself so I've only put a bit of thought into this section.
As far as I'm aware we don't break BOM support for UTF-8, though we may wish to have a different BOM to strictly distinguish UTF-8 from UTF-8000. Maybe UTF-8000 could have multiple BOMs, one for each integer N greater than or equal to four, to indicate to a decoder the maximum expected code unit length.
One of the reasons why U+FFFE is not a valid Unicode Scalar Value is because 0xFE 0xFF is the BOM for UTF-16. Since UTF-16 code units are two bytes wide, one may read either 0xFE 0xFF or 0xFF 0xFE depending on endianness. To make it clear that 0xFF 0xFE implies correct for endianness
and cannot be mistaken for a legitimate character, U+FFFE is designated as <noncharacter-FFFE>. We are relieved in that neither 11111111 11111110 nor 11111110 11111111 are valid UTF-8000 sequence extracts, ie UTF-8000 does not introduce incompatibilities with UTF-16.
Arbitrary Lengths, Sensible Limits
I think we've made it clear by now that UTF-8000 code units can be arbitrarily large. In practice however one may wish to set a sensible limit on code unit lengths when decoding. Here we'll discuss a method of finding some nice code unit lengths whose code units store 5n+1 = 2^N bits, as we are often interested in powers of 2 in computer science.
It is a common observation that 3-byte UTF-8 stores 5 * 3 + 1 = 16 bits, meaning the Basic Multilingual Plane of Unicode can be encoded in one two and three byte UTF-8. We see that 2^4 mod5 = 16 mod5 = 1 mod5; if 5n+1 is to be 2^N for some n then certainly 2^N = 1 mod5. If we enumerate powers of two modulo five then there is a very predictable repeating pattern of 1, 2, 4, 3
. Formally you might say that 2 is a generator of 𝔽5* if you want impress a mathematician! The takeaway is that when N=4K for K≥1 we can find a corresponding n such that 5n+1 = 2^N. We can rewrite 2^N as 2^(4K) = 16^K.
In other words any power of 16 has a UTF-8000 code unit length containing that many digits
. Here are a few of these for reference.
K |
N=4K |
number of content bits = 2^N |
code unit length = (2^N - 1) / 5 |
|---|---|---|---|
1 |
4 |
16 |
3 |
2 |
8 |
256 |
51 |
3 |
12 |
4096 |
819 |
4 |
16 |
65536 |
13107 |
... |
... |
Do remember that strictly speaking one shouldn't allow overlong encodings if one were for example thinking of storing a small uint256_t key in a 51 byte code unit!
Intuitive Derivation
There are a few ways that one could arrive at the design for UTF-8000 and the bit counts above.
One may think to start with UTF-8, notice that the start byte of an n byte code unit is prefixed with the unary codeword of length n+1, that is n 1 bits followed by a 0, and then figure out how to extend those bits and roll them over into the continuation bytes without losing any important properties. This is what I originally did.
Writing this document over a couple of weeks made me introspect the code unit anatomy further, whence I figured out that separating the leading bits into a self-synchronization part and self-punctuation part further illuminates and simplifies the thought process. We shall thus proceed with this perspective.
Blank Slate
We set out to derive the design of an n byte code unit, starting out with n blank bytes, all of whose bits could possibly be content bits.
00000000
00000000
00000000
...
00000000
To achieve self-synchronization we need to distinguish the first byte of the code unit from the continuation bytes that follow. We could do that by setting the highest bit of first bytes to a
0 and to 1 for continuation bytes. Doing it this way round maintains compatibility with ASCII's highest bit being 0.
00000000
10000000
10000000
...
10000000
With the design so far, all code units begin with an ASCII byte. When decoding a code unit, we have no idea whether this first byte actually is ASCII, or it is the first byte of a multi-byte code unit. We want self-punctuation, where a code unit intrinsically tells us how long it is.
To achieve self-punctuation we create a prefix-free code binary tree, whose leaf node codewords correspond to code unit lengths. These are the start bits sequences. The codeword for n shall be embedded inside the code unit towards the start. It must therefore be short enough to fit into the n bytes, and reasonably computationally predictable. We try:
.----0 One byte UTF-8 (ASCII)
`----1---0 Two byte UTF-8
`----1---0 Three byte UTF-8
`----1---0 Four byte UTF-8
`----1---0 Five byte UTF-8000
`----... n byte UTF-8000
This seems reasonably simple so far. We stripe the start bits into the available bits not taken by the self-synchronization prefix. All other bits shall be content bits.
| 1 |
00xxxxxx
|
|||||
| 2 |
010xxxxx
|
1xxxxxxx
|
||||
| 3 |
0110xxxx
|
1xxxxxxx
|
1xxxxxxx
|
|||
| ... | ||||||
| 17 |
01111111
|
11111111
|
1110xxxx
|
1xxxxxxx
|
... |
1xxxxxxx
|
| ... |
But wait we've broken the distinction of ASCII! We cannot tell the difference between eg
0110xxxx
and
0110xxxx, or
01111111
and
01111111. This code would only work if ASCII were six-bit instead of seven-bit. Out of curiosity we investigate this code in the rejected alternatives section ASCVI
.
To maintain compatibility with ASCII we must treat it as a special case, whereby the self-synchronization prefix 0 is alone sufficient to characterize ASCII. This highlights that the architecting of UTF-8 was not purely a mathematics problem, but was also an engineering problem, working around what already exists.
Seeing the ASCII-characterizing prefix 0 and the erstwhile continuation prefix 1 as forming a prefix-free tree, albeit only of size two, we must repurpose the the latter codeword as the beginning of the self-synchronization prefixes for first bytes and continuation bytes of multi-byte code units. We choose our new self-synchronization prefixes as 11 for start bytes and 10 for continuation bytes. This produces the following tree:
.----0 First byte for ASCII
`----1---0 Continuation byte for multi-byte UTF-8000
`----1 First byte for multi-byte UTF-8000
Accordingly adjusting the self-punctuation codewords to apply only to multi-byte code units produces the following tree:
.----0 Two byte UTF-8
`----1---0 Three byte UTF-8
`----1---0 Four byte UTF-8
`----1---0 Five byte UTF-8000
`----... n byte UTF-8000
Putting these mechanisms together yields UTF-8000 and we're done!
| ASCII | |||||||||||
| 1 |
0xxxxxxx
|
||||||||||
| UTF-8 | |||||||||||
| 2 |
110xxxxx
|
10xxxxxx
|
|||||||||
| 3 |
1110xxxx
|
10xxxxxx
|
10xxxxxx
|
||||||||
| 4 |
11110xxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
|||||||
| UTF-8000 | |||||||||||
| 5 |
111110xx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
||||||
| 6 |
1111110x
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
|||||
| 7 |
11111110
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
||||
| 8 |
11111111
|
100xxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
|||
| 9 |
11111111
|
1010xxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
||
| 10 |
11111111
|
10110xxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
|
| ... | |||||||||||
| 22 |
11111111
|
10111111
|
10111111
|
10110xxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
| ... |
It is a trivial* result of coding theory that the product of two prefix-free codes is also a prefix-free code. The product of our trees looks like:
.----0 ASCII byte
`----1---0 UTF-8 continuation byte
`----1---0 Two byte UTF-8 start byte
`----1---0 Three byte UTF-8 start byte
`----1---0 Four byte UTF-8 start byte
`----1---0 Five byte UTF-8000 start byte
`----... n byte UTF-8000 start byte
Without the color highlighting this is how most people think about UTF-8: a start byte whose prefix of n 1 bits and a terminating 0 bit provides both self-synchronization and self-punctuation, and continuation bytes using a short prefix of 10 for space-efficient encoding. This makes sense for a small number of bytes, but the trick to unlock a perspective of infinite extensibility is to split this tree into the self-synchronization part and self-punctuation part; ie we un-product those prefix-free codes. Failing to do this leads to the rejected alternative UTF-Infinity.
Encoding
Couple of ways
Decoding
Couple of ways

Error Recovery
Further Ideas
Signed Variant: ZigZag Encoding
So far we have used UTF-8000 to encode codepoints, aka non-negative integers, aka unsigned integers. I have come up with a couple of modified interpretations of the content bits which allow us to encode the entire integers, aka the signed integers.
We make use of a marvelous bijective mapping between the signed integers and unsigned integers called the zigzag function
that remains a bijection when restricting to the respective n-bit ranges. We use this as a final layer at the beginning/end of the standard UTF-8000 encoding/decoding procedure.
Source
ZigZag encoding from Protobuf by Google: Protocol Buffers Documentation / Encoding
Myself: This seems like the perfect extensible solution for how to encode signed integers on top of UTF-8000.
TLDR / Examples
The code unit structure is identical to UTF-8000. The content bits correspond to the image of the zigzag function.
zigzag(z) |
z |
UTF-8000 |
|
|---|---|---|---|
| ... | ... | ... | |
124 |
62 |
01111100
|
|
125 |
-63 |
01111101
|
|
126 |
63 |
01111110
|
|
127 |
-64 |
01111111
|
|
128 |
64 |
11000010
|
10000000
|
129 |
-65 |
11000010
|
10000001
|
130 |
65 |
11000010
|
10000010
|
131 |
-66 |
11000010
|
10000011
|
| ... |
The ZigZag Function
The zigzag function maps from the signed integers to the unsigned integers.
If z ≥ 0 then zigzag(z) = 2 * z = (z << 1)
If z < 0 then zigzag(z) = -2 * z - 1 = -(z << 1) - 1 = ~(z << 1)
z |
zigzag(z) |
|---|---|
| ... | ... |
-4 |
7 |
-3 |
5 |
-2 |
3 |
-1 |
1 |
0 |
0 |
1 |
2 |
2 |
4 |
3 |
6 |
| ... | ... |
zigzag(z) |
z |
|---|---|
| ... | ... |
0 |
0 |
1 |
-1 |
2 |
1 |
3 |
-2 |
4 |
2 |
5 |
-3 |
6 |
3 |
7 |
-4 |
| ... | ... |
______________
/ __________ \
/ / ______ \ \
/ / / __ \ \ \
/ / / / \ \ \ \
-4 -3 -2 -1 0 1 2 3
\ \ \ \_____/ / /
. \ \_________/ /
. \_____________/
.
The ASCII art above illustrates the enumeration of the preimage of zigzag, showing it zigzagging between positives and negatives. This should make it clear how after 2^N steps we have covered exactly the range [-2^(N-1), 2^(N-1)).
For example the preimage of the 7-bit unsigned range [0, 128) is the 7-bit signed range [-64, 64).
Branchless ZigZag
If one is dealing with fixed-width integers, for example mapping from int32_t to uint32_t, one can create a branchless version of zigzag, wow! CPUs like branchless code.
With this example zigzag(z) = (z << 1) ^ (z >> 31), where
here is the C bitwise-xor operator.
^
If 2^31 > z ≥ 0 then (z >> 31) = 0, because we have filled the register with the highest bit of a non-negative signed number, 0. Thus zigzag(z) = (z << 1) ^ (z >> 31). Okay, nothing special?
But if -2^31 ≤ z < 0 then (z >> 31) = -1, because we have filled the register with the highest bit of a negative signed number, 1. Aha, so to achieve the bitwise complement, ~(z << 1), we can bitwise-xor with this -1. Thus zigzag(z) = (z << 1) ^ (z >> 31).
Properties
Self-synchronization, self-punctuation, and arbitrary code unit length have the same conclusion as base UTF-8000. Properties that differ are discussed below.
Encoded Range
The content bit counts work the same as they do for UTF-8000. Below is a summary of the ranges of integers that the content bits encode.
| code unit length | number of content bits | minimum integer | maximum integer |
|---|---|---|---|
n = 1 |
7 |
-2 ^ (7n-1) ( = -64) |
+2 ^ (7n-1) - 1 ( = +63) |
n ≥ 2 |
5n+1 |
-2 ^ (5n) |
+2 ^ (5n) - 1 |
Small Integers, Small Code Units
UTF-8000 is really just a variable-width bit container with some nice properties. Provided that we obey the forbidding of overlong encoding, we can use the content bits as we please, encoding from an arbitrary alphabet to unsigned integer codewords that form the content bits.
The alphabet in question for us is the signed integers, ℤ. We heuristically think of magnitude as a measure of commonness. The closer an integer is to zero, the more common it is, and thus the smaller the unsigned integer that it should be encoded as, whence the shorter the UTF-8000 code unit it occupies. This is almost common sense.
We have observed that zigzag achieves this. Two's complements in a fixed-width register however does not do this, as for example in a 64-bit CPU register the number -1 is encoded as 111...[64]...11. This is not a problem for hardware like CPUs, but we are interested in efficient encoding for transmission and storage.
Modified strcmp(3) Ordering
Since the negative integers are interwoven (zigzagged) between the non-negative integers via zigzag, we lose strcmp ordering from UTF-8000. For example -1 < 0 but 00000001 > 00000000. However, being undeterred we can supersede this fact.
The purpose of strcmp(s1, s2) with respect to UTF-8000 is to quickly compare code units s1 and s2 as a proxy for comparing their contained codepoints, without having to actually decode the code units. For this modified version of UTF-8000 we wish to create a quick proxy for comparing the contained signed integers.
The only variants of UTF-8000 that can make exact use of strcmp are those whose content bits encode letters from a totally-ordered alphabet, for which there exists an order-preserving bijection between that alphabet and the unsigned integers. Since the unsigned integers has a minimum element, 0, and the signed integers (our alphabet) does not have a minimum element, no such bijection exists.
We know that zigzag(z) breaks nicely into two cases, non-negative signed integers and negative signed integers. We also know that order-preserving bijections do exist between 0) non-negative signed integers and the even unsigned integers, and 1) negative signed integers and the odd unsigned integers. We initially break our new strcmpsigned(s1, s2) function into four cases depending on the final bit of each code unit, which we know is a content bit and indicates whether the stored unsigned integer is even or odd. We can obtain these bits via b1 = c1 & 1 and b2 = c2 & 1 where c1 and c2 are the final bytes of the respective code units:
b1 |
b2 |
comment |
b2 - b1 |
1 - b1 - b2 |
|---|---|---|---|---|
0 |
0 |
s1 ? s2 |
0 |
1 |
0 |
1 |
s1 > s2 |
1 |
0 |
1 |
0 |
s1 < s2 |
-1 |
0 |
1 |
1 |
s1 ? s2 |
0 |
-1 |
If b2 - b1 is non-zero then strcmpsigned can return that, as we are effectively comparing two signed integers of a different sign. Otherwise (1 - b1 - b2) * strcmp(s1, s2) effectively compares two integers of the same sign. We could therefore write this as:
strcmpsigned(s1, s2) = (b2 - b1) ? (b2 - b1) : (1 - b1 - b2) * strcmp(s1, s2)
That's pretty succinct! I have also assumed that strcmp is just the simple {-1, 0, +1} version.
Verdict
I like it! I'll add it to the reference implementation when I get chance. It will most likely be a flag
for -zzigzag
used like $ utf-8000 info -z -- -67 showing 11000010 10000101.
This zigzag variant has a big advantage over the rejected two's complement signed variant in that we don't need to change how we do overlong checking from the standard UTF-8000 method. This means that we can effectively separate out into layers
: 1) the overlong checking of code units and the extracting of their content bits, from 2) the further decoding of the content bits eg to a signed integer.
The only external metadata needed when decoding a stream of UTF-8000 bytes is is this unsigned or signed?
. This is no different to decoding a stream of raw bytes, or inspecting fixed-width integers stored in two's complement form in a CPU register: it's up to the programmer's use-case to know whether signed or unsigned is expected.
UTF-16K
Could we apply some techniques from this document to also extend UTF-16? Yes, but at the cost of forbidding more codepoints from being encoded similar to the surrogate range U+D800 to U+DFFF.
UTF-16 is a bit messy in its existing two-byte and four-byte form, but we can clean this up in a mostly forwards-compatible manner by using ASCVI-on-UTF-16. We assume the use of big-endian UTF-16 in this section.
Source
Myself: Realizing that I can challenge the UTF-16 extensions proposed by UCS-X.
TLDR / Examples
| 2 |
xxxxxxxx xxxxxxxx
|
||||||
| 4 |
110110xx xxxxxxxx
|
110111xx xxxxxxxx
|
|||||
| 8 |
11011011 0000xxxx
|
110111xx xxxxxxxx
|
11011011 001xxxxx
|
110111xx xxxxxxxx
|
|||
| 12 |
11011011 00010xxx
|
110111xx xxxxxxxx
|
11011011 001xxxxx
|
110111xx xxxxxxxx
|
11011011 001xxxxx
|
110111xx xxxxxxxx
|
|
| 16 |
11011011 000110xx
|
110111xx xxxxxxxx
|
11011011 001xxxxx
|
110111xx xxxxxxxx
|
11011011 001xxxxx
|
110111xx xxxxxxxx
|
... |
| 20 |
11011011 0001110x
|
110111xx xxxxxxxx
|
11011011 001xxxxx
|
110111xx xxxxxxxx
|
11011011 001xxxxx
|
110111xx xxxxxxxx
|
... |
| ... | |||||||
| 72 |
11011011 00011111
|
11011111 11111111
|
11011011 00110xxx
|
110111xx xxxxxxxx
|
11011011 001xxxxx
|
110111xx xxxxxxxx
|
... |
| ... | |||||||
| 136 |
11011011 00011111
|
11011111 11111111
|
11011011 00111111
|
11011111 11111111
|
11011011 001110xx
|
110111xx xxxxxxxx
|
... |
| ... |
Properties
Two-byte UTF-16 is just the raw binary form of any 16-bit codepoint, except for the surrogate
range U+D800 to U+DFFF of size 2048 which any Unicode encoding (UTF-8, UTF-16, UTF-32) is forbidden to encode. The reason for this exclusion is because otherwise we could not distinguish 110110xx xxxxxxxx from 110110xx xxxxxxxx and 110111xx xxxxxxxx from 110111xx xxxxxxxx which you'll read about below.
Four-byte UTF-16 is two surrogate codepoints stuck next to each other, one high
in the range U+D800 to U+DBFF and one low
in the range U+DC00 to U+DFFF. The real codepoint that they encode is 0x10000 added to the 20 binary digit number contained in the content bits within. For example 11011000 00001000 11011100 00101101 contains 0x0202D, which then has 0x10000 added to it, to give 0x1202D. U+1202D is 𒀭
, a Mesopotamian Dingir.
To expand UTF-16 indefinitely instead of being stuck with 0x110000 (1,114,112) codepoints, we employ ASCVI inside of UTF-16 surrogate pairs. UTF-8 was able to expand from 7-bit ASCII without any trouble because bytes with the highest bit set were undefined. In UTF-16 however every possible value that the content bits can take defines a codepoint. The best that we can do, so that we do not interfere with already assigned codepoints, and so that we do not malapportion too many unassigned codepoints for UTF-16K, is to constrain ourselves to a single unassigned plane, Plane 13. This plane is nice as the surrogates take the form 11011011 00xxxxxx 110111xx xxxxxxxx, the highest two bits of the second byte being zero. The codepoints U+D0000 to U+DFFFF are to be forbidden from being encoded, just as the 2048 surrogates of the Basic Multilingual Plane are.
We use these four-byte containers as the quantum for UTF-16K, which uses two or more of these quanta to extend from UTF-16. The content bits encode the codepoint's binary representation, without adding on 0x10000 for the sake of simplicity, similar to UTF-8000.
Bit Counts
| number of bytes | number of content bits | number of mandatory content bits |
|---|---|---|
n = 2 |
16 |
0 |
n = 4 |
20 |
0 |
n = 8 |
29 ( = 3.5n + 1) |
9, or codepoint ≥ 0x110000 |
n = 4k ; k ≥ 3 |
14k + 1 ( = 3.5n + 1) |
14 |
Overlong checking is complicated for the jump from 4 bytes to 8 bytes, because of the 0x10000 that is added to the content bits. Either one of the highest 9 bits has a non-zero bit, or the 2^20 bit is active and one of the 2^m bits is active with 16 ≤ m ≤ 19.
Information Rate
For 2-byte UTF-16 this is technically 16 / 16 = 100%, notwithstanding the surrogate range.
For four bytes this is 20 / 32 = 62.5%, slightly worse than UTF-8.
For beyond four bytes this is (14k+1) / (4k*8) = 7/16 + 1/(32k) which approaches 7/16 = 43.75%, not great.
Below is a comparison of the efficiencies of UTF-8 and UTF-16.
| start | end | range size | number of UTF-8 bytes | number of UTF-16 bytes |
|---|---|---|---|---|
U+0000 |
U+007F |
0x80 = 128 |
1 (ASCII) |
2 |
U+0080 |
U+07FF |
0x780 = 1,920 |
2 |
2 |
U+0800 |
U+FFFF |
0xF800 = 63,488 |
3 |
2 |
U+10000 |
U+10FFFF |
0x100000 = 1,048,576 |
4 |
4 |
UTF-16 is more efficient than UTF-8 only at encoding U+0800 to U+FFFF, aka the three-byte UTF-8 range that UTF-16 encodes using two bytes.
For ASCII, and beyond U+10FFFF (using UTF-8000 or UTF-16K), UTF-8000 is far more efficient (and less ugly).
Self-Synchronization
UTF-16K does not have self-synchronization at the byte level because UTF-16 does not. If one experiences a single missing byte then potentially the whole stream becomes corrupted.
At the two-byte level UTF-16 has self-synchronization which UTF-16K inherits. Non-surrogate codepoints are quantum; they are to UTF-16 as ASCII is to UTF-8. Surrogate pairs provide self-synchronization with their 110110 and 110111 high and low surrogate prefixes.
UTF-16K goes even deeper, using multiple surrogate pairs that usurp and shadow Plane 13, to encode arbitrary codepoints. Within the surrogate-pair self-synchronization level, within the high surrogates used to encode UTF-16K, 11011011 00xxxxxx, ASCVI is employed, whose leading bit provides self-synchronization, with 11011011 000 and 11011011 001.
Therefore overall UTF-16K exhibits self-synchronization at the two-byte level, like UTF-16.
Self-Punctuation
Inherited from ASCVI.
Compatibility
UTF-16K forbids Plane 13 of Unicode, because it has no way to encode those codepoints, instead repurposing the surrogate pairs erstwhile required to encode Plane 13 for the purpose of encoding codepoints beyond 0x110000. An important question to ask regarding forwards compatibility is what does an existing UTF-16 parser do if it meets a UTF-16K code unit?
.
In short it's Plane-13-garbage-in Plane-13-garbage-out. Each surrogate pair used in encoding a UTF-16K codepoint beyond 0x110000 would be parsed separately, but with no syntactic issues. Semantically however this would cause issues with character (codepoint) counts that would count each surrogate pair as a separate character, rather than contributing towards a single character.
I believe that this may be a better solution than UCS-X's UTF-G-16 which breaks syntactic compatibility with UTF-16 by repurposing low surrogates as leading units
for UTF-G-16 6-byte code units. One could argue that UTF-G-16 is better because those bytes would be replaced with a single replacement character �
though I'm not convinced, as for example the default behavior of Python's bytes.decode function is 'strict', which raises an exception, not 'replace' which produces replacement characters.
Verdict
I don't care for UTF-16. The immature part of me says let UTF-16 decay and die as the short-sighted, legacy, Windows,
. But it will be around for a while, with several uses, like the Joliet Filesystem for my beloved Arch Linux ISOs grrr.
wchar_t, non-self-synchronizing-at-the-byte-level, +0x10000, garbage that it is
The main reason I wrote this section was to provide an alternative to UCS-X, so that we can use the same(ish) style as UTF-8000, and lest UCS-X or an even uglier idea come along.
The requirement to extend the list of codepoints that one is forbidden from encoding, to include Plane 13 or elsewhere, would not be an easily achieved feat.
For modern choices UTF-8 / UTF-8000 is undoubtedly the way to go.
UTF-32K
In the same manner that ASCII is extended by UTF-8 and UTF-8000, UTF-32 could also be extended to be a multi-byte
(32-bit chunk) encoding scheme.
Source
Myself: It seemed obvious how this follows from UTF-8000.
TLDR / Examples
We could extend UTF-32 either in the style of UTF-8000, treating the one-byte
code units as a special case occupying the lower 31 bits...
| 1 |
0xxxxxxx_xxxxxxxx_xxxxxxxx_xxxxxxxx
|
|
| 2 |
110xxxxx_xxxxxxxx_xxxxxxxx_xxxxxxxx
|
10xxxxxx_xxxxxxxx_xxxxxxxx_xxxxxxxx
|
| ... |
...or in the style of ASCVI, with no special cases and the one-byte
code units occupying the lower 30 bits.
| 1 |
00xxxxxx_xxxxxxxx_xxxxxxxx_xxxxxxxx
|
|
| 2 |
010xxxxx_xxxxxxxx_xxxxxxxx_xxxxxxxx
|
1xxxxxxx_xxxxxxxx_xxxxxxxx_xxxxxxxx
|
| ... |
Properties
Mutatis mutandis, the properties of UTF-8000 and ASCVI apply. We only make further remarks on a couple of properties.
Bit Counts
Predictable like ASCVI.
| number of bytes | number of content bits | number of mandatory content bits |
|---|---|---|
n = 4 |
30 |
0 |
n = 4k ; k ≥ 2 |
30k |
30 |
Information Rate
Whilst the ASCVI-style UTF-32K has an information rate of 30 / 32 = 93.75%, it is very inefficient for low-value codepoints, with the highest bytes most often being zeros. UTF-8000 has a much finer telescopic expansion mechanism at the byte level, compared to UTF-32 at a four-byte level.
Self-Synchronization
UTF-32 is not self-synchronizing at the byte level, and UTF-32K inherits this weakness. UTF-32 is only self-synchronizing at the four-byte level, similar to how UTF-16 is only self-synchronizing at the two-byte level. UTF-32K maintains self-synchronization at the four-byte level.
Endianness
Like UTF-16, and unlike UTF-8 and UTF-8000, UTF-32 has endianness, its quantum being a whopping four bytes.
Verdict
Not our greatest priority.
UTF-32 is hardly ever used for transmission or storage due to its inefficiency and endianness. Its main use is for when one decodes UTF-8 or UTF-16 to int32_t integers (UTF-32) for use inside a program.
Rejected Alternatives
Although UTF-8000 extends naturally
from UTF-8, is it still the best approach? Are there any better alternatives that engineer
an extension from UTF-8, just as UTF-8 engineers an extension from ASCII?
We rule out a few alternatives in this section. It's good to document the suboptimal solutions (and outright failures) so that we can work towards success. I've done that plenty of times with my own ideas don't worry! Feel satisfied in having at least made an attempt.
ASCVI
What if ASCII were only six-bit instead of seven-bit? Would this make extending to multi-byte code units more pleasant?
Source
Myself: The intuitive derivation section of UTF-8000.
TLDR / Examples
| 1 |
00xxxxxx
|
|||||
| 2 |
010xxxxx
|
1xxxxxxx
|
||||
| 3 |
0110xxxx
|
1xxxxxxx
|
1xxxxxxx
|
|||
| ... | ||||||
| 17 |
01111111
|
11111111
|
1110xxxx
|
1xxxxxxx
|
... |
1xxxxxxx
|
| ... |
Properties
Self-synchronization, self-punctuation, strcmp ordering, BOM support, and arbitrary code unit length have the same conclusion as UTF-8000. Properties that differ are discussed below.
Bit Counts
The number of content bits and mandatory content bits are even more predictable than those of UTF-8.
| code unit length | number of content bits | number of mandatory content bits |
|---|---|---|
n = 1 |
6n ( = 6) |
0 |
n > 1 |
6n |
6 |
This is because one-byte code units are not special. They use the same 0 self-synchronization prefix as any first byte. The number 6 arises from every subsequent continuation byte adding on 7 more content bits, minus 1 for the longer start bits sequence.
Consequently the number of content bits stored in an n byte code unit is never a power of two, unlike with UTF-8000. This is because 6, containing 3 in its prime factorization, cannot divide into a power of two. This is not a terrible defect, but we do like powers of two.
Information Rate
ASCVI's information rate is 6n / 8n = 6 / 8 = 75%. This a constant independent of the length of the code unit.
For one-byte code units UTF-8000 (ASCII) is more efficient and versatile, storing double the number of codepoints and having an information rate of 87.5%.
For multi-byte code units ASCVI is more efficient, with UTF-8000's information rate tending downwards towards 62.5%.
Even if the US English alphabet had its 52 letters cut down to eg 27 Hebrew glyphs, or no letters at all, one would struggle to create a practical set of 64 glyphs for single-byte ASCVI. The tradeoff of ASCII being seven-bit, at the slight detriment of the information rate of multi-byte code units, seems worth it.
Byte Map
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 5 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 6 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| 7 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 5 | 5 | 5 | 5 | 6 | 6 | 7 | 8+ |
| 8 | ||||||||||||||||
| 9 | ||||||||||||||||
| A | ||||||||||||||||
| B | ||||||||||||||||
| C | ||||||||||||||||
| D | ||||||||||||||||
| E | ||||||||||||||||
| F |
Unlike UTF-8000 which can never use the bytes 0xC0 and 0xC1, ASCVI uses all 256 possible bytes. Which of these is the advantageous behavior depends on whether one wants to do something extraordinary with those two bytes, or one wants to dissuade their use in chicanery.
Intuitive Derivation
See the intuitive derivation of UTF-8000 for how one might come up with this.
Naming
The II
in ASCII reminds me of the Roman Numerals VII
for seven, and ASCII is a seven-bit code. Therefore for this six-bit code we choose to use the Roman Numerals for six, VI
, and name it ASCVI
.
Verdict
7 bit ASCII, and UTF-8 that extends it, are very well established. One-byte ASCVI is inferior to the flexibility of ASCII, albeit this contributes to UTF-8 having a slightly lower information rate for multi-byte code units. I do not yearn for an alternate universe, or a fresh start of text encoding standards, where ASCII is six-bit instead of seven.
That being said, ASCVI is by no means inherently flawed, and we can make use of it in UTF-16K and UTF-32K.
Signed Variant: Two's Complement
One might be shocked to find our beloved two's complement representation of the signed integers present in the rejected ideas section. This is not about one's personal taste in representing signed integers, but technological extensibility, with which the zigzag signed variant far outshines this two's complement variant.
Source
Myself: It seemed like a good(ish) idea until I realized that the zigzag variant is better.
TLDR / Examples
We treat the n content bits of a code unit as a two's complement signed form, where the highest bit no longer has value 2 ^ (n-1) but rather -2 ^ (n-1).
| ASCII | |||||
| 1 |
0xxxxxxx
|
||||
| UTF-8 | |||||
| 2 |
110xxxxx
|
10xxxxxx
|
|||
| 3 |
1110xxxx
|
10xxxxxx
|
10xxxxxx
|
||
| 4 |
11110xxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
|
| UTF-8000 | |||||
| 5 |
111110xx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
10xxxxxx
|
| ... |
The difference in code unit layout from UTF-8000 is that the mandatory content bits are downshifted by one bit.
Properties
Overlong Encoding Checking
Preventing overlong encoding requires checking that the content bits of an n-byte code unit encode an integer z from the range [ -2^(5n), +2^(5n) ) \ [ -2^(5(n-1)), +2^(5(n-1)) ). This may look complicated, but we can break it down into two cases:
For z ≥ 0, the highest content bit of both n-byte and n-1-byte code units is 0. There must be at least one 1 bit in the following bits, which are the mandatory content bits.
For z < 0, the highest content bit of both n-byte and n-1-byte code units is 1. This is to make z negative, using the -2^(5n) bit. There must be at least one 0 bit in the following bits, which are the mandatory content bits. Otherwise if all of these bits were ones, then z would be at least -2^(5(n-1)). For example the overlong encoding
11011111
10000000 encodes z = -64 which fits into a 1-byte code unit. Encoding integers below -64 requires subtracting from these content bits, which sets at least one of the mandatory content bits to zero.
UTF-8000 never uses the bytes 0xC0 and 0xC1, which is explained in the glossary section for overlong encoding. Slightly differently, this two's complement signed variant never uses the bytes 0xC0 (11000000) or 0xDF (11011111).
No strcmp(3) Ordering
Since negative integers set the highest content bit to 1, we lose strcmp ordering from UTF-8000. For example -1 < 0 but 01111111 > 00000000.
Verdict
A big downside of this two's complement signed variant is that its anti-overlong checking mechanism differs from that of UTF-8000 because of the 1-bit-downshifted position of the mandatory content bits. Consequently it is not possible to agnostically decode a stream of these bytes as though they were UTF-8000 bytes. For example, a 0xC1 byte is valid in this variant as 11000001, but is invalid in UTF-8000 as 11000001.
What if we tried to redeem this variant by proposing to move the negative
bit, the -2^(5n) bit, to the stable tail end of the code unit, rather than it being at the ever-expanding head of the code unit? This could hopefully mean that we would not have to change the anti-overlong checking mechanism from UTF-8000. The long and short is that we would perchance intuitively reinvent the zigzag signed variant from first principles, which indeed leftwards bitshifts by one the signed integer that it encodes, using the lowest bit as the negative
bit. Our redemption is found there.
UTF-Infinity
What if we naively roll the start bits
over into further bytes?
Source
Mashpoe on YouTube: Expanding the UTF-8 Character Set to Infinity
TLDR / Examples
| ... | ||||||
| 7 |
11111110
|
10xxxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
|
| 8 |
11111111
|
0xxxxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
|
| 9 |
11111111
|
10xxxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
|
| 10 |
11111111
|
110xxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
|
| ... | ||||||
| 15 |
11111111
|
11111110
|
10xxxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
| 16 |
11111111
|
11111111
|
0xxxxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
| 17 |
11111111
|
11111111
|
10xxxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
| 18 |
11111111
|
11111111
|
110xxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
| ... |
Properties
Bit Counts
Effectively, every jump from 8k-1-byte code units to 8k-byte code units the encoding inserts another blank byte after the start bytes, by which 8 minus 1 equals 7 bits of content are gained in an ASCII-looking byte, instead of appending a continuation byte by which 6 minus 1 equals 5 bits of content are gained.
| code unit length | number of content bits | number of mandatory content bits |
|---|---|---|
n = 1 |
7 |
0 |
n ≠ 8k |
5n+1 + 2⌊n/8⌋ |
5 |
n = 8k |
5n+1 + 2⌊n/8⌋ |
7 |
Information Rate
For an n-byte code unit the information rate is UTF-8000's information rate plus 2⌊n/8⌋ / (8n).
I'm not working it out fully, but I can tell that this leads to a sawtooth-y profile as a graph of information rate against n. Therefore, counterintuitively, longer code units can have better efficiency than shorter ones.
No Self-Synchronization
In the 8-byte code unit example, there is no way to distinguish the second byte 0xxxxxxx from an ASCII byte 0xxxxxxx. This generalizes to 8n-byte code units.
In the 15-byte code unit example, there is no way to distinguish the second byte, 11111110 from the first byte of a 7-byte code unit. This generalizes to 8n-1-byte code units.
In the 16-byte code unit example, there is no way to distinguish the second byte, 11111111 from the first byte of an 8-byte code unit. This generalizes such that if one seeks to any 11111111 byte, one has no idea if this is the first byte of a code unit or not.
This list is non-exhaustive.
Self-Punctuation
This is the property that Mashpoe clearly prioritized preserving, however the approach was too myopic and did not lead to preserving other properties of interest.
Patented
Mashpoe jokes (?) in the video that he owns the patent to this encoding scheme.
Regardless of whether he is joking or not, I nonetheless find it reprehensible that someone could (at least try to) copyright / patent the correct way to extend UTF-8. It would be like trying to copyright the right solution to a mathematics equation, or a prime number! Therefore I am being quite loud in the copylefting of UTF-8000 in the licensing section. Everyone benefits from shared, free-as-in-freedom, open ideas.
Verdict
The loss of self-synchronization is a fatal detriment.
The formula for the number of content bits has predictable but irritable jumps, which lead to counterintuitive information rates.
UCS-X
TLDR / Examples
Perl utf8
Use up to 7 bytes to encode up to 36 bits of information in the sane way, in order to encode 32-bit integers (and a little beyond). To encode 64-bit integers, use a special-case fixed 13-byte code unit starting with 11111111.
Since the n-byte code units with n < 8 are the same as UTF-8000 we shall mostly only discuss the 13-byte code units.
Source
Perl5 on GitHub: utf8.h
A comment reads: A note on nomenclature: The term UTF-8 is used loosely and inconsistently in Perl documentation ... perl uses an extension of UTF-8 to represent code points that Unicode considers illegal.
.
TLDR / Examples
| ... | |||||
| 6 |
1111110x
|
10xxxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
| 7 |
11111110
|
10xxxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
| 13 |
11111111
|
10xxxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
Properties
Bit Counts
There are no code units of length 8, 9, 10, 11, or 12. Nor are there any of length 14 or beyond.
| code unit length | number of content bits |
|---|---|
n = 1 |
7 |
1 < n < 8 |
5n+1 |
n = 13 |
72? |
Why 13 Bytes Instead Of 12?
Encoding the maximum possible signed 64-bit integer, 0x7FFF_FFFF_FFFF_FFFF, in Perl utf8 returns 11111111 10000000 10000111 ... 10111111. Even if the maximum possible unsigned 64-bit integer, 0xFFFF_FFFF_FFFF_FFFF, were encodable it would fit into the lower 11 bytes. So why use 13 bytes instead of 12, with the second byte always 10000000?
My guess is that the designers were going to use a UTF-Infinity style 11111111 11111000 opening, but then they recognized that they would lose self-synchronization because the second byte looks like the start of a 5-byte utf8 sequence. Therefore they swapped the second byte to a 10000000. They could have removed it and used 12 bytes, but that would preclude any future reunification with e.g. UTF-8000, which with 12 bytes has only 5 * 12 + 1 = 61 content bits which is less than 64, but with 13 bytes has 5 * 13 + 1 = 66 which is sufficient.
Information Rate
On the surface 13-byte, 72-bit code units have an information rate of 72 / (13*8) = 72 / 104 = 69%, which is better than that of UTF-8000 (62.5%).
However as only 64 of those 72 bits are used in encoding 64 bit numbers, with the whole of the first continuation byte never being used, the information rate is closer to 64 / (13*8) = 64 / 104 = 61.5%, which is worse than UTF-8000.
Self-Synchronization
This is effectively the same as UTF-8000. All continuation bytes have a 10 self-synchronization prefix, and the 13-byte start byte 11111111 has a 11 self-synchronization prefix.
Self-Punctuation
The first byte of a 13-byte code unit being 11111111 characterizes it as a special case, providing self-punctuation. This is similar to ASCII being a special case with its characterizing prefix of 0 in the highest bit.
Not Infinitely Extensible
Because Perl only supports up to 64-bit numbers without a specialized bigint module, it was sensible of them to cap their extension of UTF-8 to a finite number of bytes. It's not the prettiest however, and I'm not sure why they chose 13 bytes when 12 would suffice. CPU alignment if they don't store the predictable start byte of all 1s?
Verdict
Inextensible, providing only one special case beyond 7-byte UTF-8
to encode 64-bit numbers, and is thus not widely known or supported.
Also, they refer to it as utf8
instead of UTF-8
(the correct way), though this is pedantry.
Owl's Corrected
UTF-8
Owl suggests a corrected
version of UTF-8 with many radical changes. Many of these are opinionated, such as removing most control codes from C0. Many are technical, such as precluding the concept of overlong encodings similarly to UTF-16, by an n-byte code unit decoding to the binary number stored in the content bits added to the upper bound of codepoint values from n-1-byte code units.
Even notwithstanding the established dominance of UTF-8, I still disagree with almost everything in the document. But, he does come the closest to discovering the structure of UTF-8000's code units.
Source
Owl's Portfolio: Corrected UTF-8
TLDR / Examples
| ... | |||||
| 6 |
1111110x
|
10xxxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
| 7 |
11111110
|
10xxxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
| 8 |
11111111
|
110xxxxx
|
10xxxxxx
|
... |
10xxxxxx
|
| 9 |
11111111
|
1110xxxx
|
10xxxxxx
|
... |
10xxxxxx
|
| ...? |
If Owl had specified the second-highest bit of his continuation start bytes to be a 0 instead of a 1 then he would have beat me to UTF-8000! So close, but so far.
Properties
No Self-Synchronization
In the 8-byte code unit example, there is no way to distinguish the second byte 110xxxxx from the first byte of a 2-byte code unit 110xxxxx. This generalizes beyond just 8-byte code units. This specific example could also encode 11000001 (0xC1), which UTF-8 cannot, which may trip UTF-8 compatibility stress-tests.
BOM Collision
Owl acknowledges that his extension may lead to issues with the UTF-16 BOM, as (presumably?) his extension permits 11111111 11111110 (0xFF 0xFE), the little-endian UTF-16 BOM.
Verdict
Owl acknowledges leaving that extension for the future
with respect to going beyond the 6-byte old RFC 2044 version of UTF-8, showing humility and acknowledging his design's flaws.
I don't wish to dunk on his document too hard, but I'm greatly relieved that he failed to derive the infinite extension mechanism. It's not just for my ego's sake, but because I do not wish for UTF-8(000) to be associated with all the other junk in his specification.
Do Nothing
Why bother publishing this now and making so much noise? As of Unicode Version 17.0, September 9th 2025, only 299,448 of 1,114,112 (27%) codepoints have been designated.
- It is a great exercise in coding theory.
- Nobody else seems to have figured it out, as only worse rejected alternatives have been previously proposed.
- If we wait until we run out of codepoints, one of those rejected alternatives may be hastily implemented just because it already exists. Granted, compatibility with UTF-16 would be broken, and first codepoints with five and six byte UTF-8 representations as per RFC 2044 could be satisfactory without needing UTF-8000.
- The current upper bound of
U+10FFFFon codepoints is entirely due to UTF-16's maximum capacity. UTF-16 andwchar_tis legacy Windows tech. If the future demands a larger set of codepoints then we should allow ourselves to not be held back. - Who doesn't like freedom, the ability to encode any integer (unsigned or signed) that we want to?
- I feel in charge of the
intellectual property
to an extent, and as such I have copylefted it, rather than allowing a tyrant to (re-)discover it and publish it on their restrictive terms. Fortune andglory. I figured this out myself in the era of the rise of AI. I'll settle for the credit lol.- I will be submitting this work to 3b1b's Summer of Mathematics Exhibition 2026.
Verdict
Publish.
Reference Implementation and Tools
Working reference implementation in Python with comprehensive code documentation is available on GitHub as UTF-8000/UTF-8000-Python.
It can be installed as a PyPI package using $ pipx install UTF-8000 which provides the command line utility utf-8000.
The $ utf-8000 info subcommand displays info about a codepoint encoded in UTF-8000, with useful bit highlighting.
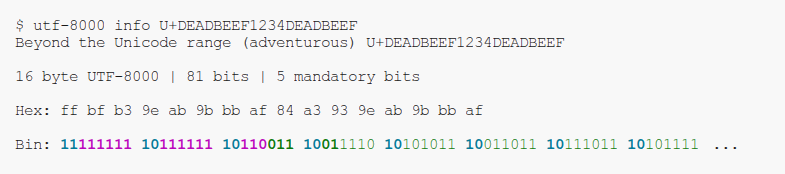
The $ utf-8000 encode subcommand reads codepoints from stdin and writes the raw UTF-8000 bytes to stdout.
The $ utf-8000 decode subcommand reads UTF-8000 bytes from stdin and feeds them to an incremental decoder, writing the decoded codepoints to stdout.
Naming
In the development phase of this project I have been using the codename UTF-8000
, but I find myself increasingly drawn to UTF-8K
.
Below is a comparison of different potential names, and I am open to suggestions.
UTF-8000
Inspired by Python 3's development codenames in PEP 3000.
Pros
- The
thousand
inUTF eight thousand
sounds big and futuristic. This encoding scheme should also last forever!
Cons
- The zeros are repetitive.
- Having to remember exactly three zeros to make
8000
. Some people may read it as eight hundred, or eighty thousand etc. - The inspiration logic doesn't exactly match up with Python because Python was moving from Python 2 to Python 3, not Python 3 to Python 3000, whereas we're going from UTF-8 to UTF-8000.
UTF-8
is a prefix ofUTF-8000
. Existing software which parses a string representing the encoding's name to determine the encoding may do something likeif encoding_name[:5] == "UTF-8"and incorrectly short-circuit. It is for this reason that Microsoft skipped from Windows 8 to Windows 10, not creating Windows 9, because existing software may check forWindows 9
to test forWindows 95
orWindows 98
.
UTF-8K
Inspired by another of Python 3's development codenames Py3K
/ Py3k
, we could use UTF-8K, the K
capitalized like the UTF
. It's also shorter than 8000
.
Pros
- Short; just one more letter than
UTF-8
.
Cons
UTF-8
is a prefix ofUTF-8K
. See here.
UTF-8 & Knuckles
The K
in UTF-8K
reminds me of Sonic 3 & Knuckles
, sometimes abbreviated to S3K
.
The Sonic & Knuckles
cartridge uses lock-on technology
to extend Sonic 3
and Sonic & Knuckles
into Sonic 3 & Knuckles
. In a similar way UTF-8 extends from (locks on to) ASCII, and UTF-8000 continues this extension.
Pros
- Knuckles is cool.
Cons
- SEGA might not be happy, though they do seem nicer than Nintendo with respect to fanart.
- The hardest work of extending from ASCII to UTF-8 has already been achieved by Ken Thompson and Rob Pike. Is UTF-8000 lock-on if it doesn't introduce any new special cases? Not really.
UTF-8
is a prefix ofUTF-8 & Knuckles
. See here.- This is just a bit of a joke-y name.
VTF-8
Short for Variable Transformation Format 8
.
Pros
- Removes the association with Unicode as VTF-8 is just a method of storing unsigned integers.
UTF-8
is not a prefix ofVTF-8
; in fact they don't even begin with the same letter.- The
V
looks Romanesque and fits with the logo.
Cons
- The
V
inVTF-8
looks very similar to theU
in UTF-8. At a glance, and depending on font rendering, one may not notice the difference.
STF-8 for the Signed Variant
The U
in UTF-8
could also be read as Unsigned
, ie Unsigned Transformation Format 8
. Thus we could take inspiration and write STF-8
for Signed Transformation Format 8
.
Logo
UTF-8 does not have a logo. I had a bit of fun designing a logo for UTF-8000. I made it Romanesque but simple.
It's an eagle with UTF
written across its wings and chest. The Roman numerals for 8
, VIII, flank its head.
Below its claws it holds a fasces, wrapped with a continuation byte of the form
10xxxxxx. This represents the united strength of a bundle of continuation bytes, which makes us unstoppable in conquering the entire integers, in the name of including them into Unicode codepoints, encoded in UTF-8000.
The central fascis which sticks out represents the first byte of a code unit. This byte looks different from its continuation bytes, and has the power to start a code unit, which is represented by the wielding of the axe, sticking out on the left. On the right end the central fascis sticks out perhaps representing the terminating 0 of the start bit sequence.
The favicon for this website is just the Roman numerals VIII.
The Git repo containing these images is available on GitHub as UTF-8000/UTF-8000-Images.
Licensing / Copyright (Copyleft)
As creator of UTF-8000 I want the liberty with which UTF-8000 (the algorithm) can be used to be no less permissible than UTF-8 and ASCII before it. This belongs to everyone. Live Free or Die.
This website is licensed under CC-BY-NC-SA-4.0, available on GitHub as UTF-8000/UTF-8000-Website.
The logo / images are licensed under CC-BY-NC-SA-4.0, available on GitHub as UTF-8000/UTF-8000-Images.
The Python reference implementation is licensed under GPL-3.0-only, available on GitHub as UTF-8000/UTF-8000-Python. Any implementation of decoding and encoding UTF-8000 is going to look somewhat similar to this codebase of course; don't worry if you want to use MIT or BSD or something else in a clean-room rewrite.
Thanks
Bell Labs:
- Claude Shannon, founding father of the Digital Age, Information Theory, and Artificial Intelligence. His 1948 paper A Mathematical Theory of Communication is the most important mathematics paper of the mid 20th Century, which forms a good chunk of the University of Cambridge Mathematics Tripos course Coding and Cryptography. I made a Manim YouTube video in 2024 covering Entropy from Information Theory and its various appearances in mathematics.
- Ken Thompson, creator of UTF-8, also best known for Unix and other big projects like chess computers.
- Rob Pike, co-creator of UTF-8, also best known for Plan 9 and other big projects.
The University of Cambridge mathematics department:
- Professor Stuart Martin, who lectured Coding and Cryptography 2019-2020.
- Dr Ross Lawther, director of studies for mathematics at Girton College who supervised me for Coding and Cryptography (and other mathematics topics!) 2017-2020. It is question 2 of example sheet 1 that concerns the product of two prefix-free codes, which I was reminded of by the product of the self-synchronization and self-punctuation mechanisms of UTF-8000.
- Dr Keith Carne, whose timeless lecture notes for Codes and Cryptography I use often. They are mirrored on my website here. Start at chapter 3 if you're interested!
Contact / Epilogue
To think of these stars that you see overhead at night, these vast worlds which we can never reach. I would annex the planets if I could.
- Cecil John Rhodes, founder of Rhodesia.
It is fitting that ASCII (🇺🇸) and UTF-8 (🇺🇸) are completed by UTF-8000 (🇬🇧), the annexing of the entire integers, another Anglosphere classic.
Do say hi on GitHub if you have any questions or improvements.
Last updated .